Catapult: A Bird’s Eye View
December 20, 2023
Transcript of talk given (virtually) at Xymposium 2023 in Tokyo, Japan. Discusses some of the motivations for Symbol (and NEM). Provides an overview of the architecture of the Catapult client.

Konnichiwa! Greetings and salutations! ¡Mucho gusto!
Thank you for joining us here today at our first ever XYMPOSIUM. I hope you all have an enjoyable time and learn a lot. It has been almost ten years since the development of NEM began in earnest, but better late than never! I'm sorry I couldn't be with you today in person, but I was in Japan this past March and was able to experience much of your beautiful country.
In this talk, I'll give you a high-level overview of the Catapult client's architecture, as well as some of the lesser known things it enables. But, first, I want to quickly talk about some of the motivations for Symbol.
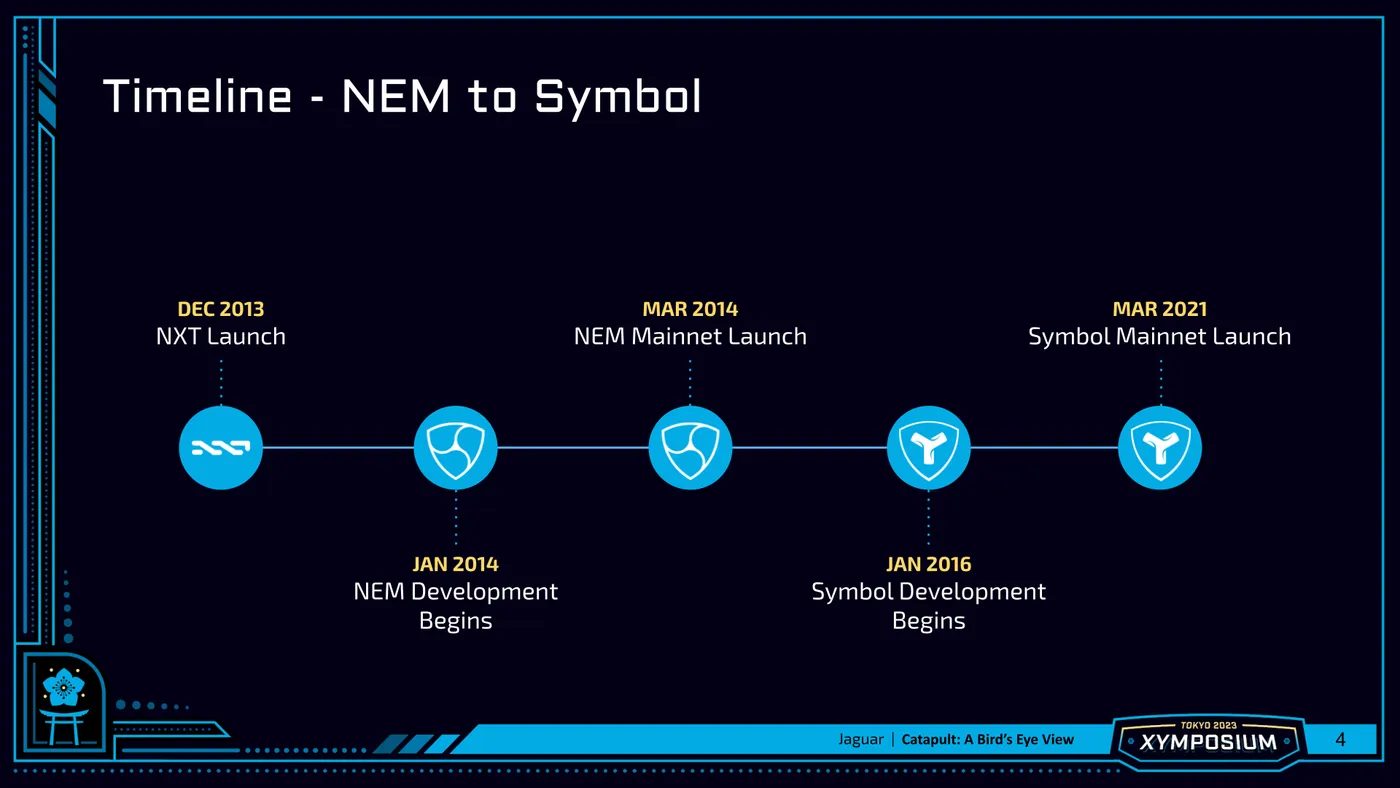
To understand Symbol, we need to take a quick trip in a time machine back to early 2014 when NEM started. It was the tail end of a Bitcoin hype cycle, accompanied by an explosion of - mostly terrible - altcoins. Bitcoin was still mostly decentralized and aligned much closer to its original principles, long before it had become a toy of Wall Street. There was a coin of that era called NXT that had a clever Proof of Stake algorithm, but a very toxic community and a very concentrated distribution. One of the NXT community members recruited developers - mostly from the NXT community - to build NEM. We wanted to improve upon the good aspects of Bitcoin and NXT and build a positive community. These were the early days of Proof of Stake, and we wanted to see what was possible. Mainly, we wanted to build something easy to use and fun.
NEM launched in March 2015 and was surprisingly successful, especially in Japan. Still, NEM was always built as more of a side project for us, rather than an enterprise grade one. Parts of the NEM client and the NEM protocol were put together in haste.

The entire NEM client was written in Java. Even at the time, we knew Java wasn’t the best choice, but we chose it to be accommodating to a handful of other developers who expressed interest in contributing early on. Eventually, they left, and we were stuck fighting with the garbage collector, which could freeze a node for seconds without warning. The verbosity and “safety” of the language also slowed us down.
There was limited parallelization. Only the verification of signatures within a single block chain part was parallelized.
The transaction serialization was never tuned properly, and there was no differentiation between fixed size and variable size binary data. As a result, the fixed size data was often prepended with redundant size information, increasing payload sizes for no good reason. Similarly, there was no differentiation between top-level and embedded transactions, so every multisig transaction contained redundant information from the embedded transaction header.
Data storage left a lot to be desired. Although transactions and blocks were stored in an H2 database, the computed state never was. As a result, the state needed to be recomputed on the fly each time a node restarted. This is the reason it takes hours to days to start up a NEM node now. In addition, there were no state hashes, so state proofs were impossible.
There weren’t even Merkle transaction hashes in the blocks, so it was impossible to quickly sync just block headers and pull transaction data lazily later on.

In 2016, a Japanese company agreed to sponsor us to use our learnings from building NEM to develop an enterprise grade blockchain - one built with security, performance and modularity in mind from the ground up. This is what became Symbol. Ease of use and fun were still our north stars, but we also wanted a very - perhaps overly - extensible client. And, that is what Catapult became!!
Catapult is the Symbol reference client and is written in C++, which lets us have fine grained control over memory usage. It is built with C++ 17, which makes C++ a modern language with lambdas and everything!
We spent a significant amount of time optimizing the layout of binary data structures to avoid unnecessary bloat. In addition, we wanted our structures to be serialization free on little endian machines. In other words, we wanted to be able to simply cast the raw data to a pointer of the correct type and be able to access the data immediately without any serialization overhead. This required our binary definitions to have perfect byte fidelity.
Unfortunately, we found “all purpose” serialization libraries - like protobuf - to be unable to support this. Most would not return access to the raw underlying buffer. Others, would insert superfluous sentinel and/or size bytes.
In order to achieve this goal, as well as making our structures easier to use, we created a custom domain specific language - or DSL - called catbuffer. In its schema files, we fully specify each payload’s binary layout with perfect byte fidelity. The official JavaScript and Python SDKs include generators that input catbuffer schema files and output corresponding types in JavaScript or Python, respectively. In this way, once we define a new transaction in a catbuffer schema, the official JavaScript and Python SDKs can support it immediately after running the respective generator. Eventually, we extended the DSL to support NEM transactions and all of their weird quirks too. This makes it easy to support dual SDKs that support both NEM and Symbol.

In Catapult, nodes establish SSL connections over TCP with each other. They communicate by sending packets of data over these connections. In order to reduce the overhead of establishing an SSL session, these connections are reused and relatively long lived.
Each packet has a simple header that indicates the size and type of data it contains. Once received by a node, the node checks the packet’s type and finds an appropriate handler. In the case of block packets received, the handler first inspects the packet to find the start of all blocks and ensures that all are fully contained in the packet’s payload. If all checks pass, the blocks are forwarded to the block disruptor.
In Catapult, a custom implementation of the LMAX disruptor pattern is used to implement the primary processing pipelines. There is a separate disruptor for blocks, transactions and, where applicable, partial transactions. All of the disruptors operate similarly in that they are composed of a number of stages - or consumers. When a payload is received, the disruptor pushes it through its consumers until it's either rejected or ultimately accepted. The specific consumers composing each disruptor are, of course, different.
It is important to understand that one of the main benefits of the disruptor pattern is that it is inherently parallel. Although a single payload is processed by only one consumer at a time and progresses through the consumers sequentially, the consumers themselves run in parallel. For example, consumer 1 could be processing item 11 at the same time consumer 3 is processing item 4. The current state of processing is tracked in a circular ring buffer.
During processing, Catapult loads transaction definitions and rules - in the form of validators and observers - from plugins, which we will examine later in this talk.

For a concrete understanding, we'll examine some of the consumers that are used by the block dispatcher to process blocks. You will notice that most of the consumers are very simple, which makes them easier to understand and test. In addition, many of the consumers used in the block dispatcher are similarly used in the transaction dispatcher.
An optional AuditConsumer writes the blocks being processed along with some metadata to a special audit folder.
This consumer is disabled by default, but it can be used to help debug problems.
The BlockHashCalculatorConsumer calculates all dependent hashes.
These include the hashes of all transactions and blocks, as well as the block Merkle hashes.
It optimistically calculates hashes once, upfront, instead of needing to recalculate them multiple times during processing, like the NEM client.
The BlockHashCheckConsumer rejects single blocks that have already been received.
As part of network synchronization, it's possible for nodes to receive newly harvested blocks from multiple nodes.
Since processing those blocks multiple times would be wasteful, we preemptively abort in such cases.
The BlockchainCheckConsumer checks for consistency within the received blocks.
For example, if multiple blocks are received, they must all be properly linked to each other.
These essentially are stateless validation checks that apply to groups of blocks.
Since these checks are across blocks, the notification system that Catapult uses to validate and apply state changes is not really applicable without adding special notifications that contain data from multiple blocks.
Instead of doing that, we use this consumer.
The BlockStatelessValidationConsumer validates all state-independent constraints.
For example, it will check that all blocks have an appropriate type set and that none contain more transactions than the configured maximum.
Since these checks are all state-independent, they are run in parallel.
The BlockBatchSignatureConsumer validates all block and transaction signatures.
This signature verification is fully parallelized, which leads to a nice performance boost - especially during syncing - because signature verification is typically one of the most expensive operations in blockchain systems.
The BlockchainSyncConsumer validates all state-dependent constraints and actually updates the blockchain state.
Importantly, this is the only consumer that requires access to the blockchain state.
Unsurprisingly, this is the most expensive consumer and, most often, the processing bottleneck.
As such, the following consumers were split out to reduce its responsibilities and keep it as lean as possible.
An optional BlockchainSyncCleanupConsumer performs some additional cleanup on nodes without a broker process present.
For recovery purposes, the Catapult client essentially writes a checkpoint to disk prior to applying changes.
This allows it to revert to that checkpoint in the case of a fault.
When the broker process is present, it automatically cleans up these checkpoint files.
When it is not, this consumer does.
The NewBlockConsumer pushes the new chain head to other nodes.
Notice that only individual blocks are pushed, not groups of blocks, which must be pulled by nodes.
This helps hasten the propagation of the new head block, which is the most common situation after the initial sync.

If you were listening carefully, you might have noticed that the disruptor for partial transactions is not always enabled.
This is because that disruptor is only added when the partialtransaction extension is enabled in the Catapult configuration.
That raises the question of what is an extension? In fact, extensions are one of two primary extensibility points of Catapult. The other is plugins, which we will get to later.
Extensions customize client functionality. They can do anything except change consensus rules. Nodes in a network may load different extensions and/or the same extensions with different configurations. In fact, the only difference between the different types of nodes - Peer, API, Dual - is the set of extensions they load.
Catapult is basically just an application shell that loads plugins and extensions, instantiates their services and lets them run.
It does slightly more than that - for example, preparing the data directory and managing the loading of saved data on boot - but not much.
Nearly all of its functionality resides in its plugins and extensions.
Even the two other disruptors - for blocks and transactions - are registered via an extension - the sync extension.
There is nothing special about this extension.
It has the same constraints and capabilities as any other extension.
The fact that block and transaction processing can be implemented in an extension, should illustrate the power of the extension model.
Drilling down a little further, there are really two types of extensions. The differences relate in how they communicate.
The first set of extensions simply receives data via event subscriptions and does something with it.
For example, the mongo extension accepts this data and commits it to a NoSQL database.
This model is simple and flexible enough to support storing data in any type of database, among other things.
It is certainly possible to load the mongo extension in the node process directly, but that approach has some downsides.
Any bugs in the mongo extension - or mongo itself - could take down the node and weaken the network.
Instead, since the mongo extension is not participating in the consensus but simply reading events, it's possible to host it in a separate process and isolate it from the main node process.
With this setup, any bugs would only take down this separate process, but the node would still be operational.
In fact, this process isolation is already supported and has been in use since launch using the broker process!
The other set of extensions push data among themselves using server hooks.
As an example, we can look at how blocks are moved into the BlockDisruptor, which is registered in the sync extension.
The sync extension additionally registers a server hook that accepts blocks and forwards them to the BlockDisruptor.
In turn, any extension that needs to process blocks simply needs to pass blocks to this hook.
Even though blocks can come from multiple sources and various extensions:
- Blocks can be pulled from other nodes in the
syncextension. - Blocks can be received from other nodes in the
syncsourceextension. - Blocks can be created or harvested in the
harvestingextension.
All of these blocks are passed to the BlockDisruptor via the hook registered in the sync extension.

After learning about extensions, now let's learn about Catapult's other primary extensibility point - plugins. Unlike extensions, plugins customize blockchain consensus. They can add transaction types, state changes and custom validation rules. All nodes in a network must load the same plugins with the same configuration.
Let's look at the parts that make up a transaction definition.
First, we need to define the transaction's binary layout in a catbuffer schema.
Second, we need to break down the transaction into Notifications.
A notification is the smallest unit that can be processed by Catapult, and, as such, can be reused across multiple plugins.
This helps reduce the amount of new code that is needed to add new functionality.
For example, we have a BalanceTransferNotification that indicates a token movement from a sender account to a recipient account.
Clearly, this is one of the components of a transfer transaction.
But, it is also used elsewhere.
For example, to deduct the namespace rental fee when registering a new namespace.
Third, we need to define validation rules that check if a notification is valid. Two types of validation rules are supported: stateless and stateful. Stateless validators check state-independent constraints. For example, signature verification and network suitability can be checked by these validators. In contrast, stateful validators require the current blockchain state. For example, checking whether or not a balance transfer is allowed requires knowing the current balance of the sender to ensure there is a sufficient balance.
Finally, we need to define the state change itself given a notification. During normal operation, an observer receives the current state and a notification and updates the state. During rollback, it receives the modified state and the same notification and undoes the modification.
Importantly, notice that both validators and observers operate on notifications, but not transactions. A key benefit of processing at the notification level is that it makes support for composite transactions seamless. In practice, this means, similar top-level and embedded transactions (i.e. transactions within aggregates) will decompose into the same notifications, excluding notifications raised by their containers, and result in the same state changes. With our design, we get this mostly for free.

That was a lot to get through in a short amount of time! I hope you have learned something and are intrigued to learn more. We've only touched on the high level design today, and there's a lot more detail in the weeds.
If you don't remember anything else from this talk, I'd like you do remember the following:
- Catapult is basically an empty application shell
- Plugins add network consensus rules and transaction support
- Extensions add almost everything else - from aggregate bonded signature aggregation to finalization
There is, by design, a lot of potential for customization. I hope some of you will use this knowledge and your imagination to add new node capabilities. If you get stuck, you can always find us on X or Discord or GitHub.
Thank you for your participation and enjoy the rest of the day!